V dnešním článku popíšu princip fungování autentizačního protokolu
OAuth a důvody pro jeho použití.
K čemu je OAuth?
Součástí jednoho našeho projektu byla integrace se sociálními sítěmi
(synchronizace kontaktů, statusů přátel, zpráv, multimediální galerie).
V našem případě to byly: Facebook, Twitter, Gmail, MSN a YouTube. Všechny
uvedené servery mají veřejné API, pomocí kterého lze k jeho funkcím
přistupovat. V prvních prototypech jsme v našich konektorech pro
autentizaci používali uživatelské jméno heslo (používala se HTTP basic
autentizace. V reálné aplikace není z různých důvodů (bezpečnost)
možné uživatelské jméno a heslo ukládat do databáze. A právě k tomu
je OAuth.
OAuth autentizace umožňuje uživatelům sdílet data, texty,
fotografie a videa uložená jednom serveru, s jiným serverem, aniž by museli
vyzradit svoje přístupové údaje.
Jak OAuth funguje?
Nejdříve si představíme základní pojmy:
- Service provider – služba, která obsahuje chráněné
zdroje a má být chráněna. Může se jednat o bankovní server,
mikroblogovací server, nebo server pro správu obrázků.
- Uživatel – reálný uživatel služby (Service
provideru), vlastník chráněného obsahu.
- Consumer – aplikace přistupující k chráněným
zdrojům uživatele. Zdroje leží na service provideru.
- Chráněný zdroj – obsah uživatele (data, texty,
obrázky, videa), který chce chránit.
Nejdříve je nutné consumer u service providera zaregistrovat. Způsoby
registrace jsou různé. Nejčastěji je to webové rozhraní. Rovnou uvedu
příklad – zvolím si Twitter. Mějme aplikaci, která se bude připojovat
na Twitter (tato aplikace je consumer) a bude si stahovat naše
nejnovější zprávy.
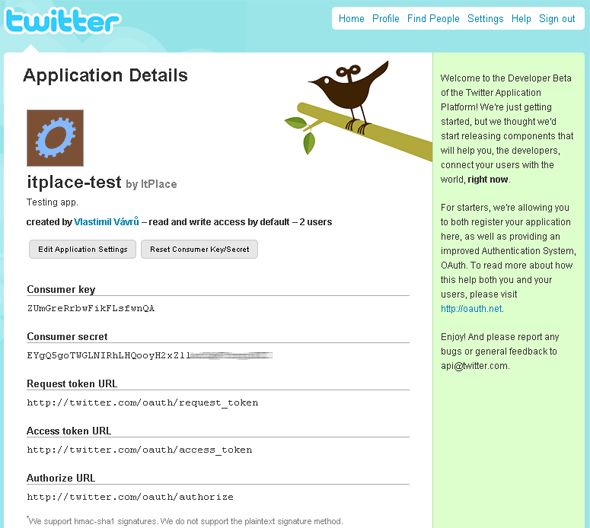
V případě Twitteru se přidá (zaregistruje) nová aplikace zde – Register an Application (pro
přidání aplikace musíte mít účet na Twitteru a být přihlášeni). Pro
ty z vás co nemají účet na Twitteru uvedu přehled nejdůležitějších
vlastností, které je možné u aplikace vyplnit:
- jméno, popis, domovská stránka aplikace
- callback URL (adresa, na kterou bude uživatel přesměrován po
nastavení práv)
- typ přístupu (read only, read and write)
Parametry aplikace nejsou povinné. Ty, jež jsem uvedl, platí pouze pro
Twitter a nejsou součástí specifikace OAuth. V jiné aplikace může být
např. granularita přístupových práv mnohem jemnější (např. přístup
pouze do určitého adresáře s fotkami a na omezenou dobu).
Výsledkem registrace consumera je consumer key a
consumer secret. Consumer key identifikuje consumera. Consumer
secret slouží pro podepisování
požadavku.
1) Získání request tokenu
Uživatel je na webu consumera a klepne na tlačítko (odkaz) pro získání
přístupu. Odkaz vede na web consumera a provede se následující:
Získání request
tokenu – provede se na serverové straně consumera (např pomocí HttpClient nebo standardní HttpURLConnection.
Na straně consumera je service provider identifikován třemi URL:
HTTP request z consumera na service provider musí být podle OAuth
standardů. Musí obsahovat povinné parametry (ty musí
být správně encodovány) a být podepsán.
Povinné parametry:
- oauth_consumer_key: The Consumer Key.
- oauth_signature_method – typ šifrování použitý pro signature
(podpis) requestu (PLAINTEXT, HMAC-SHA1, RSA-SHA1)
- oauth_signature – podpis zprávy (postup vytvoření podpisu bude
popsán)
- oauth_timestamp – klasický Unix timestamp označující dobu vytvoření
requestu
- oauth_nonce – unikátní číslo requestu
- oauth_version – verze (nepovinný parametr). Současná hodnota
je 1.0.
Vytvoření podpisu (hodnoty parameru oauth_signature):
- Shromáždí se veškeré parametry (kromě parametru „realm“) –
query parametry, POST parametry, parametry z OAuth hlavičky
- Parametry se převedou do kódování UTF-8 (kromě binárních dat) a
provede se URL encodování
- Parametry jsou seřazeny
podle abecedy a spojeny v jeden řetězec
- Z řetězce se pomocí consumer secret a token secret vygeneruje podpis a
přidá se jako parametr oauth_signature do requestu
Výsledný request:
GET /oauth/request_token HTTP/1.1
Host: twitter.com:80
Authorization: OAuth realm="http://twitter.com/oauth/request_token"
oauth_consumer_key="asdfasqeiou235sd"
oauth_token=""
oauth_nonce="2345667878"
oauth_timestamp="1230768000"
oauth_signature_method="HMAC-SHA1"
oauth_version="1.0"
oauth_signature="4TbFhc%2FDKyGswotg39339AR4J5k%3D"
Výsledkem zavolání requestu je request token a request token
secret.
2) Přesměrování na stranu service providera
Uživateli je vrácen response, který v hlavičce přesměrovává
na URL pro autentizaci uživatele na straně service providera.
V případě Twitteru je to adresa http://twitter.com/oauth/authorize.
Jako parametry jsou poslány request token (získaný v předchozím kroku) a
volitelně callback URL (adresa pro přesměrování po
nastavení přístupových práv na straně service providera).
3) Nastavení přístupových práv
Na straně service providera se uživatel přihlásí a povolí consumerovi
přistupovat k aplikaci. O různých typech přístupových práv jsem mluvil
dříve v článku.
4) Přesměrování zpět na consumera
Následuje přesměrování zpět na consumera na zadanou callback URL. Jako
parametr je poslán request token, aby consumer věděl,
k čemu vlastně byla práva nastavena.
5) Consumer požádá o access token
Consumer na straně serveru vytvoří HTTP request stejně jako v bodu
1 při získávání request tokenu. Rozdíl je v cílové URL service
providera – nyní je to URL pro výměnu request token za access token. Pro
Twitter je to http://twitter.com/…access_token.
Když je přístup pro daný request token povolen, je navrácen access
token a access token secret. Tím je celý proces
dokončen.
Access token je součástí OAuth hlavičky, access token secret se
používá současně s consumer secret pro podepsání requestu.
Předchozích 5 bodů musí uživatel v ideálním případě obsolvovat
pouze jednou. Záleží na typu aplikace – někdy se nastavuje přístup na
omezenou dobu. Pak záleží pouze na tom, zda service provider po nějaké
době access token nevyexpiruje. Podle našich zkušeností to ale tak
nevypadá. Např. Google tvrdí, že access token neexpiruje nikdy.
Přístup consumera k chráněnému zdroji
Nyní může consumer přistupovat k chráněným zdrojům. Abyste dostali
lepší představu co mohou být chráněné zdroje, a jak k nim přistupovat,
podívejte se na Twitter API. Např.
pomocí metody http://twitter.com/friends/ids.xml
můžete dostat všechny přátele vybraného uživatele.
Jak je to s podporou OAuth u sociální sítí a dalších webů?
Přímo na domovském webu OAuth je možné se dočíst, že jej podporují
následující weby: Digg, Jaiku, Flickr, Ma.gnolia, Plaxo, Pownce, Twitter, and
hopefully Google, Yahoo. Článek, který informace obsahuje je téměr 2 roky
starý, takže nyní bude situace ještě o mnoho lepší. Např Twitter,
který má OAuth podporu stále jenom v beta provozu, tvrdí, že po jeho
ostrém spuštění po nějaké době zruší možnost autentizace pomocí HTTP
basic authentication. Cituji:
Can my application continue to use Basic Auth?
There is no requirement to move to OAuth at this time. If/When a date is set for
the deprecation of Basic Auth we will publish a notice on the API Development
Talk. We will not set a date for deprecation until several outstanding issues
have been resolved. When we do set a date we plan to provide at least six months
to transition.
Rozdíl mezi OAuth a OpenID
OpenID neskrývá identitu uživatele.
Slouží pouze k jejímu ověření. Zatímco pomocí OAuth umožňuje
přístup ke zdrojům bez přímého udání identity uživatele
(uživatelského jméne, hesla a další osobních údajů). Každý
z autentizačních mechanizmů se proto hodí pro různé použití. Bez
zajímavosti není, že oba protokoly mají společné autory.
Závěr
OAuth je dnes již standardním způsobem autentizace, který používají
největší hráči na trhu (Google, Yahoo, YouTube, Twitter). Čas investovaný
do jeho porozumění a implementace se rozhodně vyplatí.
Odkazy
Vlastimil Vávrů Internet obecně