V tomto článku bych se chtěl podělit o praktické zkušenosti
s JBPM. Článek
neobsahuje všechny informace ani výčet všech vlastností JBPM, mým cílem
je vám ukázat, jak jsme JBPM použili v jednom z našich projektů.
Zadání
Představte si následující požadavek na váš nový blogovací
systém:
Uživatel přidává nový článek. Na základě konfigurace se provede
jedna z těchto variant:
- Bez moderace: Článek je ihned vytvořen a zveřejněn.
- Moderace apriori: Článek je vytvořen, poslán k ověření moderátorem,
pokud jej moderátor akceptuje, je zveřejněn.
- Moderace aposteriori: Článek je vytvořen a zveřejněn, poslán
k ověření moderátorem, pokud jej moderátor odmítne, je označen jako
neveřejný.
Analýza
Jaké operace nad článkem tedy náš systém musí podporovat?
- Vytvořit neveřejný článek;
- zveřejnit článek;
- zneveřejnit článek;
- smazat článek;
- poslat článek ke schválení moderací.
Z těchto operací nyní můžeme sestavit kteroukoli z variant.
Nejjednodušší je v našem případě varianta bez moderace, my se však
zaměříme na variantu moderace apriori. Konfigurace našeho systému musí
definovat, která z variant se provede, tedy které operace, v jakém pořadí
a za jakých podmínek se provedou – jinými slovy konfigurace musí
definovat proces vytvoření článku. Samotná moderace může nějakou chvíli
trvat, bude tedy třeba provádění procesu po odeslání článku k moderaci
přerušit a pokračovat až moderátor o článku rozhodne. Variantu moderace
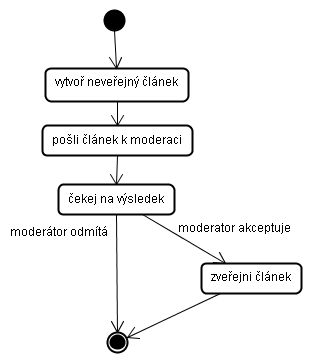
apriori můžeme znázornit jako stavový diagram:
Návrh
Jak funguje moderace? Poslání článku k moderaci si můžeme představit
jako přidání článku do fronty. Moderátor tento článek z fronty vybere a
rozhodne. Je tedy zřejmé že náš proces musíme rozdělit do dvou
asynchronních částí, provádění bude probíhat ve dvou vláknech:
Vlákno 1:
- vytvoř neveřejný článek
- pošli článek k moderaci
- konec vlákna
Vlákno 2:
- vyber článek z fronty
- moderátor rozhodne, jestli akceptovat či odmítnout
- pokud moderátor akceptuje, zveřejni článek
- konec vlákna
Jak budeme operace spouštět? Jak si zapamatovat, kde jsme v provádění
procesu skončili? Jak pak pokračovat v provádění existujícího procesu?
Jedna z možných odpovědí na tyto otázky je použít JBPM. Co JBPM
nabízí?
- JBPM je nástroj pro spouštění business procesů.
- Pomocí jazyka JPDL (Jboss Process Definition Language) lze snadno a
přehledně definovat graf procesu.
- Definice procesů lze verzovat. To v praxi znamená, že pokud změníme
definici procesu, právě probíhající instance tohoto procesu to
neovlivní.
- Jsou podporovány i takzvané wait-states, uzly ve kterých se provádění
procesu zastaví.
- JBPM obsahuje podporu pro persistenci procesů. Stav právě
probíhajících procesů je uložen v databázi.
- Instance procesu může používat procesní proměnné které jsou také
ukládány spolu se stavem v databázi.
- Na přechody i na uzly lze navázat akce.
- Snadná integrace se Springem.
- Nástroj pro grafický návrh procesů.
Nechci tady popisovat všechny vlastnosti JBPM ani JPDL, na stránkách Jboss
můžete najít výbornou dokumentaci. Dejme se tedy rovnou do implementace.
Implementace
Ukažme si, jak bude vypadat definice procesu moderace apriori v jazyce
JPDL, jednotlivé části si pak vysvětlíme:
<process-definition
name="createArticle" xmlns="urn:jbpm.org:jpdl-3.2">
<start-state name="start state">
<transition to="create invisible article"/>
</start-state>
<node name="create invisible article">
<event type="node-enter">
<action config-type="bean"
class="blog.handler.CreateInvisibleArticle">
</action>
</event>
<transition to="send to moderation"/>
</node>
<node name="send to moderation">
<event type="node-enter">
<action config-type="bean"
class="blog.handler.SendToModeration">
</action>
</event>
<transition to="wait for moderation"/>
</node>
<state name="wait for moderation">
<transition to="process decision"/>
</state>
<decision name="process decision">
<transition to="make visible">
<condition>#{decision.accept == true}</condition>
</transition>
<transition to="end">
<condition>#{decision.accept == false}</condition>
</transition>
</decision>
<node name="make visible">
<event type="node-enter">
<action config-type="bean"
class="blog.handler.MakeVisible">
</action>
</event>
<transition to="end"/>
</node>
<end-state name="end" />
</process-definition>
Takže JPDL není nic jiného než XML které popisuje graf business procesu.
Vidíme, že se tento graf skládá z uzlů, přechodů a akcí. Speciálním
typem uzlu je stav. V našem procesu máme hned tři stavy: „start state“,
„wait for moderation“ a „end“. Provádění procesu, se v těchto
uzlech zastaví. Jak bude vypadat kód, který vytvoří novou instanci procesu
a spustí ji?
public void createArticle(Article article) {
JbpmContext context = jbpmConfiguration.createJbpmContext();
try {
ProcessInstance instance = context.newProcessInstance("createArticle");
instance.getContextInstance().setTransientVariable("article", article);
instance.signal();
System.out.prntln("stopped in state: "+instance.getRootToken().getNode()
.getName());
} finally {
context.close();
}
}
Zde již počítáme s tím že máme připravenou konfiguraci JBPM
v proměnné jbpmConfiguration. Nová instance procesu, kterou zde
vytváříme se nachází ve stavu „start state“. Akce, které se budou
v průběhu provádění instance procesu spouštět, budou potřebovat vědět
jaký článek vytváříme. Proto nastavíme proměnnou „article“. Tato
proměnná může být transientní, protože nepotřebujeme aby její hodnotu
JBPM ukládalo v databázi.
Zavoláním instance.signal() se spustí samotné provádění.
Provádění probíhá synchronně, tedy ve stejném vlákně a když se dostane
do prvního stavu, v našem případě „wait for moderation“, pak
probíhání skončí a tím i provádění metody signal(). Naše
metoda vypíše na standartní výstup řádek:
stopped in state: wait for moderation
Teď se podíváme, jak funguje spouštění akcí. Akci lze pověsit na
událost. V našem případě na událost typu „node-enter“. Akce musí
implementovat rozhraní org.jbpm.graph.def.ActionHandler. JBPM
vytvoří novou instanci třídy uvedené v atributu class tagu
action a zavolá metodu execute. Implementace třídy
blog.handler.CreateInvisibleArticle může vypadat
třeba takto:
package blog.handler;
import blog.Article;
import org.jbpm.graph.def.ActionHandler;
public class CreateInvisibleArticle implements ActionHandler {
public void execute(ExecutionContext executionContext) throws Exception {
Article article = executionContext.getContextInstance()
.getTransientVariable("article");
article.setVisible(false);
getArticleDao().saveArticle(article);
}
...
}
Tato implementace počítá s tím, že instance procesu obsahuje
transientní proměnnou „article“ a jednoduše volá DAO vrstvu, aby
článek uložila. Jak bude naimplementovaná metoda
getArticleDao() není tématem tohoto článku. K tomuto problému
se vrátím v jíném článku, ve kterém se budu věnovat integraci JBPM se
Springem.
Podobně bude vypadat implementace blog.handler.MakeVisible:
package blog.handler;
import blog.Article;
import org.jbpm.graph.def.ActionHandler;
public class MakeVisible implements ActionHandler {
public void execute(ExecutionContext executionContext) throws Exception {
Article article = executionContext.getContextInstance()
.getTransientVariable("article");
article.setVisible(true);
getArticleDao().updateArticle(article);
}
...
}
Zbývá nám poslední akce blog.handler.SendToModeration:
package blog.handler;
import blog.Article;
import org.jbpm.graph.def.ActionHandler;
public class SendToModeration implements ActionHandler {
public void execute(ExecutionContext executionContext) throws Exception {
Article article = executionContext.getContextInstance()
.getTransientVariable("article");
long processInstanceId = executionContext.getProcessInstance().getId();
getModerationQueue().add(article, processInstanceId);
}
...
}
Zajímavá je zde lokální proměnná processInstanceId,
k tomu abychom po moderátorově rozhodnutí mohli v provádění procesu
pokračovat, musíme vědět ke které instanci procesu se moderovaný článek
vztahuje. Proto do moderační fronty posíláme i id instance procesu. Toto id
pak využijeme pro získání existující instance procesu. Následující
metoda je zavolána když moderátor akceptuje článek:
...
public void acceptArticle(Article article, long processInstanceId) {
JbpmContext context = jbpmConfiguration.createJbpmContext();
try {
ProcessInstance instance = context.getProcessInstance(processInstanceId);
System.out.println("currently in state: "+instance.getRootToken().getNode()
.getName());
instance.getContextInstance().setTransientVariable("article", article);
Decision decision = new Decision();
decision.setAccept(true);
instance.getContextInstance().setTransientVariable("decision", decision);
instance.signal();
System.out.println("stopped in state: "+instance.getRootToken().getNode()
.getName());
} finally {
context.close();
}
}
...
Nejprve si vyžádáme instanci procesu podle processInstanceId, stejně jako
v metodě, createArticle musíme nastavit transientní proměnnou
„article“, aby další akce měly přístup k článku. Dále nastavíme
transientní proměnnou „decision“, která obsahuje informaci o tom, jak
moderátor rozhodl. Poté se zavolá metoda signal(), čímž dojde
k pokračování instance procesu. Metoda acceptArticle vypíše
na standardní výstup:
currently in state: wait for moderation
stopped in state: end
Proměnná decision se používá při rozhodování, který
přechod použít z uzlu „process decision“:
<decision name="process decision">
<transition to="make visible">
<condition>#{decision.accept == true}</condition>
</transition>
<transition to="end">
<condition>#{decision.accept == false}</condition>
</transition>
</decision>
JBPM v uzlu typu „decision“ vybere první přechod, jehož podmínka je
splněna. Pokud není žádná podmínka splněná, vybere se první definovaný
přechod.
Závěr
Viděli jste, jak jsme postupovali a jak a proč jsme se rozhodli pro JBPM.
Zatím to vypadá, že jsme zvolili správně. S dostatečně velikou množinou
akcí, lze pohou změnou definic procesů měnit chování našeho systému.
Zdroje
Jan Šmuk Java Java, JBPM